



BBR是GOOGLE 提出的一种新型拥塞控制算法
问题引入
之前在美国买了一个VPS, 用来搭建网站, VPS是CN2-GIA?(其实是GT)的线路去程和回程都是走的59.43的节点, 延迟,丢包啥的都还挺好. 这次是复购, 之前买了一个在搞活动的VPS, 发现挺好, 就又买了一个.
买了之后就把网站迅速搭建好了, 发现速度很慢啊, 这跟预期完全不合. 明明都是同一个线路, 同一家的VPS怎么网速相差那么多, 之后想到了BBR. 开启BBR之后网络连接速度明显提升. 我才想起来之前的VPS我是开启过BBR的, 但是经过这次经历我知道了BBR算法原来这么给力!
BBR
BBR是Google 提出的一种新型拥塞控制算法,可以使Linux服务器显著地提高吞吐量和减少TCP连接的延迟。Google已经开源了该算法,并提交到了Linux内核,从4.9开始,Linux内核已经用上了该算法。也就是说只要是4.9以上的Linux内核都可以直接开启BBR. 如果低于4.9的话还是升级一下吧.
BBR 算法与之前的 TCP 拥塞控制相比有什么优势?
复杂的原理啥的就不多提, 传统的TCP拥塞控制算法(TCP Reno版本)的加法增大和乘法减小导致在有一定丢包率的线路上会收敛的一个较小的值, 使得线路带宽不能完全有效的被利用. 谷歌的BBR算法则避免了这个问题.
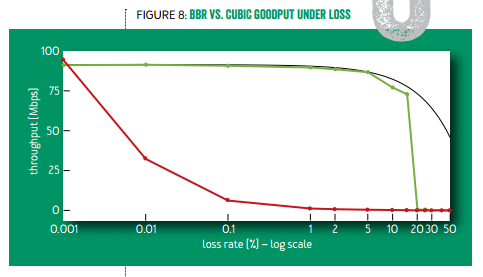
如下图所示,只要有万分之一的丢包率,标准 TCP 的带宽就只剩 30%;千分之一丢包率时只剩 10%;有百分之一的丢包率时几乎就卡住了。而 TCP BBR 在丢包率 5% 以下几乎没有带宽损失,在丢包率 15% 的时候仍有 75% 带宽。
如何开启BBR
首先, 你的Linux内核版本要大于4.9, 使用root用户运行. 然后输入下面是方法一:
echo 'net.core.default_qdisc=fq' | tee -a /etc/sysctl.conf
echo 'net.ipv4.tcp_congestion_control=bbr' | tee -a /etc/sysctl.conf
sysctl -p
完成后,执行命令:
sysctl net.ipv4.tcp_available_congestion_control
输出应为:net.ipv4.tcp_available_congestion_control = bbr cubic reno
再执行命令:
sysctl -n net.ipv4.tcp_congestion_control
输出应为 bbr
最后执行命令:
lsmod | grep bbr
返回值有 tcp_bbr 模块即说明bbr已启动!
一把梭:
echo 'net.core.default_qdisc=fq' | tee -a /etc/sysctl.conf
echo 'net.ipv4.tcp_congestion_control=bbr' | tee -a /etc/sysctl.conf
sysctl -p
sysctl net.ipv4.tcp_available_congestion_control
sysctl -n net.ipv4.tcp_congestion_control
sudo:
echo 'net.core.default_qdisc=fq' | sudo tee -a /etc/sysctl.conf
echo 'net.ipv4.tcp_congestion_control=bbr' | sudo tee -a /etc/sysctl.conf
sudo sysctl -p
sudo sysctl net.ipv4.tcp_available_congestion_control
sudo sysctl -n net.ipv4.tcp_congestion_control
方法二:
sed -i '/net.core.default_qdisc/d' /etc/sysctl.conf
sed -i '/net.ipv4.tcp_congestion_control/d' /etc/sysctl.conf
echo "net.core.default_qdisc = fq" >> /etc/sysctl.conf
echo "net.ipv4.tcp_congestion_control = bbr" >> /etc/sysctl.conf
sysctl -p
reboot
实测好像不重启也可以
验证BBR是否已经启动。
sysctl net.ipv4.tcp_congestion_control
返回值一般为:net.ipv4.tcp_congestion_control = bbr
其实, 用
lsmod | grep bbr
如果输出 tcp_bbr 的话就说明bbr已经开启了.
评论区